The issues identified in of part one of this post led to yet another search for solutions to the problem of making (especially passive) measurement repeatable. Of course, this has been done before, but I took as an initial principle that the social aspects of the problem must be solved socially, and worked from there. What emerged was a set of requirements and an architecture for a computing environment and set of associated administrative processes which allows analysis of network traffic data while minimizing risk to the privacy of the network’s end users as well as ensuring spatial and temporal repeatability of the experiment. For lack of a better name I decided to call an instance of a collection of data using this architecture an analysis vault.
The key principle behind this architecture is if data can be open, it should be; if not, then everything else must be.
Certain types of data are not at all threatening to privacy, e.g. simple active latency measurements between networks. To advance Internet measurement as a science, such data should be made as open as possible to as wide a community as possible; this is the approach taken by RIPE Atlas. However, data derived from passive measurements must be handled more carefully, and can never be completely opened. In order to support science with these data sources, all other aspects of the analysis must in these cases be made open.
This model relies on the use of analysis source code being openly licensed and made publicly available, along with the parameters for each particular analysis. Analyses are submitted by trusted researchers to a vault by repository URL and checked against a user-provided hash of the contents to verify integrity, as experiments within the mLab project. This repository contains all necessary parameters for running the desired analysis. Analysis code is reviewed for being obviously benign and following the principle of least access: if there is any doubt as to whether a given analysis is designed to only use and produce the minimum information necessary for its stated task, the analysis will not be run.
Of course, this model is only applicable to improving the repeatability of measurement if multiple vaults are built containing the same kind of data.What follows is as far as I got with the high-level design of these analysis vaults last year, followed by a quick subset of the reasons they’ll never work. But I hope this post will inspire others to consider the construction of similar vaults around currently closed or partially open data sources, and I stand ready to assist in the creation of communities around this model of data exchange.
A Process for Building and Operating Analysis Vaults
An analysis vault is a collection of data stored in some published format, or available via a certain application programming interface (API), which for some reason cannot be openly published. In the context of this work, this is generally because the data collection as a whole contains privacy-sensitive information, e.g. mobility data (which can be used to track the movements of mobile phones, and therefore their owners) or packet header or network flow data (which can be used to track the behavior of users of the network).
An analysis vault is made available by a provider, who owns the data within the vault and makes it available to a community of analysts. While analysis vaults do provide both technical and administrative protection against privacy risks, the providers must trust the analysts somewhat more that they would random people on the Internet. A coordinator manages building these communities of trust around sets of providers and analysts: introducing analysts to providers and vouching for analysts based upon their history of responsible use, matching research questions with data that can answer them, and so on. The coordinator also assigns code reviewers to each project, who are responsible for signing off that the analysis source is obviously benign.
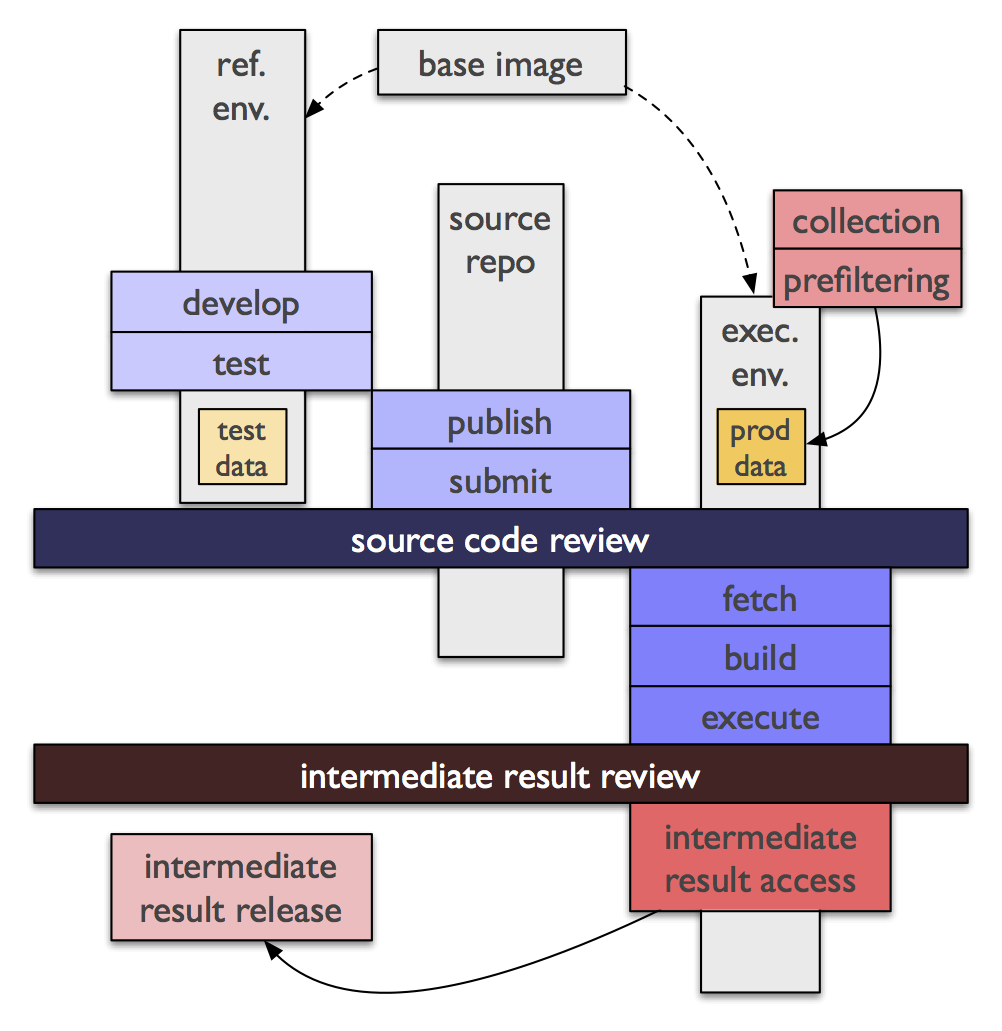
Each analysis vault is built upon a minimal amount of technical infrastructure. Each vault is built from a base image, a virtual machine image providing the basic operating environment plus any tools or API implementations for the data format that will be provided. From the base image, a reference image is derived which additionally includes some test data, which can be used by analysts to test the correctness of their analysis code.
To run an analysis, the analyst submits to the coordinator or provider:
a URL for a public source code repository containing the source code, human-readable description, build instructions, and parameters of the analysis, including any necessary identifier of branch / tag / commit.
some cryptographic assurance that the identified source is what the analyst intended to submit (e.g., a GPG-signed hash of a tarball containing a clean working copy).
Once the submission is made, the coordinator checks to see if the code in the indicated repository differs from code that has already been reviewed, and if not, sends it to the reviewer(s). Unless the reviewers are certain, based on the source code, build instructions, and parameters provided, that the analysis is benign – i.e., will return an appropriate amount of appropriately aggregated or anonymized data for visualization, further analysis, or publication, for the stated purpose, explicitly avoids any obfuscation that would indicate an attempted side channel in the output, and so on – then the analysis request is rejected.
Should an analysis request be accepted, the reviewers and/or provider also review the output data after the analysis runs, to ensure that it meets the expectations of volume, content, format, and so on from the code review. For analyses resulting in wider publication (e.g. at academic conferences or in journals), the reviewers and/or provider can also review the final product, according to each provider’s policies.
The output of this process is intended to be intermediate, that is, input to some visualization, aggregation, publication, or further analysis process which can take place in a less restricted environment. The intermediate results may not necessarily be non-sensitive enough for unrestricted publication, but should at least be able to be shared with other researchers and/or providers in contact with the same coordinator. It is these intermediate results, together with open sharing of the code and parameters that produced them, that allows this model to achieve repeatability in Internet measurement.
Specifically not part of this model is a requirement to use a specific restricted query language, or restrictions on the languages or platforms which can be used to perform an analysis. As long as any software beyond what is in the base image is available from a published URL in source form, and the provider and reviewer are comfortable with it, the analysts can use their own favorite language. The only technical requirements on the source repository are that they must contain the following three items:
a portable POSIX shell script
build.shwhich will retrieve and authenticate any necessary software beyond what is provided in the base image.a portable POSIX shell script
run.shwhich takes an parameter indicating the data to operate on (filesystem path or URL for an API) and which itself contains any necessary parameters for the analysis, including clear indications of where on the filesystem intermediate analysis products will be stored.a
README.txt,README.html, orREADME.mdfile containing a human-readable description of what the analysis is supposed to do, and any other information about the analysis and its assumptions.
Nothing is to be assumed about the provider execution environment except that it contains all the software included in the base image, and that the build script will be run once, followed by the run script.
The inherently batch-process-based workflow required within an analysis vault is apparently difficult to reconcile with tight cycles most scientists use when investigating new and unknown problems. Further, the additional requirement for code review, and the administrative overhead required to coordinate and perform these reviews, make this process significantly less flexible than processes allowing direct access to raw data. I would argue that the ability to expand data access to more parties, allowing reproduction of passive network measurement studies, is worth the additional cost. Further, by designing studies to perform analysis in a dedicated data reduction stage before performing iterative exploration, this exploration can be performed on the intermediate results in a less restrictive environment.
Encouragement of Best Practices
In addition for reviewing the proposed analysis code for being obviously benign, the coordinator and reviewers are well-placed to encourage research projects targeted for execution within analysis vaults to follow best practices in research data curation. The requirement for analysts to open analysis source code and to publish it in a publicly accessible repository, along with a single entry point to run an analysis, enforces design for repeatability. This model moves the burden of data curation from analysts to the providers and coordinator; maintenance of metadata along with data should be encouraged by coordinators bringing new providers into a community, and community resources should include detailed information about data quality issues. Beyond this, coordinators should maintain their own set of best practices, perhaps using Paxson as a starting point, which they encourage within their community of providers and analysts.
Challenges to Analysis in the Vault
This model as proposed has a few open issues which must be resolved before it is to be workable.
First, the proposed solution to the problem defines two new roles not currently part of most research workflows: code reviewers and coordinators. Both roles require a fair amount of expertise, and neither role is well-aligned with present incentives for researchers. Finding people to perform these tasks will therefore either rely on altruism, adjustment of incentives, or money (i.e. the universal incentive adjuster). Indeed, a project I was working on last year to build a pilot analysis vault fell apart in part over cost uncertainty in the coordination role. Convincing funding sources that this is a working solution to a relevant problem (indeed that is it a relevant problem at all) would be neither easy nor quick.
Second, while this model replaces technical controls which have been shown to be ineffective with contractual and social controls which I hope will be more effective, it remains that at the end of the day it is (1) naïve trust and (2) the threat of expulsion from the community and potential civil and criminal penalties that will keep researchers in line. When the only effective sanction is so drastic, it is natural to ask whether it will be used when it needs to be. A more gradual continuum of sanctions would make responsible oversight more likely.
Third is the question of who provides compute services for the first stage analysis in the analysis vault? The answer to this question nowadays is almost always The Cloud, which would also fix the problem that the academic publishing schedule tends to impose a rather bursty demand curve. However, cloud services cost money – indeed, for covering baseline demand, rather more money than a large organization would spend on the maintenance of equivalent infrastructure, which is why there’s a market for cloud services in the first place. Charging researchers for compute cycles would be a natural model here, though this seems very close to a “pay to play” model which feels antithetical to the spirit of open scientific investigation. The data provider would pay for storage costs, but this raises the bar for participation as a data provider. It also raises the question of whether it is appropriate for data providers to place data on storage in the cloud that they cannot simply make openly available to trusted researchers.
I don’t have have good answers to these questions, which is, to be honest, why you’re reading about this on my relatively insignificant blog as opposed to in a more respectable academic venue. But I suspect I’ll continue working in passive measurement research, and I’ll take every opportunity I find to nudge us closer to a model that, at least in its goals of repeatability, looks like the one here.
Acknowledgements
Thanks to the many people who have tolerated my rants about how ruined things are over the past year or so, and discussed ways to make it better: the Bernhards Ager, Plattner, and Tellenbach, Richard Barnes, Elisa Boschi, Alberto Dainotti, Alessandro Finamore, Joe Hildebrand, Diana Joumblatt, Alistair King, Mirja Kühlewind, Franziska Lichtblau, Matt Mathis, Stephan Neuhaus, Ilias Raftopoulous, Florian Streibelt, and Ariane Trammell.